Suppose we are given a sequence of N data points x = {x1, . . . , xN }. As an estimation problem, we could say that we are looking for the model that has generated this data. In other words, we try to estimate a vector of parameters θ = [θ1, . . . , θL] of a statistical model Pθ(x) for the data x. The MDL criterion is an effective way to select the optimal probabilistic model from among various models. In order to do that, it selects the statistical model with the minimum description length for the given data. The description length Dj(x) for data x of an underlying probabilistic model j is given by,
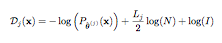
where:
• θˆ(j) represents the ML estimate of model j for the vector of parameters θ.
• Lj is the number of parameters of θˆ(j) in probabilistic model j.
One of the advantages of the MDL criterion is that the second term defined in the equation works as a penalty imposed for employing a large model size. So, as a model becomes more complex, the value of the first term decreases and that of the second term increases.
See:
Rissanen, J. (1984). Universal coding, information, prediction, and estimation. IEEE Transactions on Information Theory, 30:629–636.