From practial point of view why was this modification applied to HTS? HTK 'still' uses ML.
Maybe the higher number of contextual features is the reason?
Would appling ML in HTS cause a severe quality degradation in synthesized speech quality?
Best Regards,
Balint Toth
2013.11.19. 21:55 keltezéssel, Xavi
Gonzalvo írta:
The MDL criterion is an effective way to select the optimal probabilistic model from among various models. When used for decision tree clustering in HMM-TTS the ML criterion stays but MDL penalises larger trees.
Suppose we are given a sequence of N data points x = {x1, . . . , xN }. As an estimation problem, we could say that we are looking for the model that has generated this data. In other words, we try to estimate a vector of parameters θ = [θ1, . . . , θL] of a statistical model Pθ(x) for the data x. The MDL criterion is an effective way to select the optimal probabilistic model from among various models. In order to do that, it selects the statistical model with the minimum description length for the given data. The description length Dj(x) for data x of an underlying probabilistic model j is given by,
where:
• θˆ(j) represents the ML estimate of model j for the vector of parameters θ.
• Lj is the number of parameters of θˆ(j) in probabilistic model j.
One of the advantages of the MDL criterion is that the second term defined in the equation works as a penalty imposed for employing a large model size. So, as a model becomes more complex, the value of the first term decreases and that of the second term increases.
See:
Rissanen, J. (1984). Universal coding, information, prediction, and estimation. IEEE Transactions on Information Theory, 30:629–636.
2013/11/19 Tóth Bálint <toth.b@xxxxxxxxxxx>
Dear All,
Is there a reason, why MDL (Minimum Description Length) is preferred oved ML (Maximum Likelihood) for building decision trees in HMM-TTS?
Thank you for your answer in advance!
Best Regards,
Balint Toth
--
Xavi.
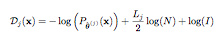
|
|
Ez a levél vírus, és rosszindulatú-kód mentes, mert az avast! Antivirus védelem aktív. |